







Developing algorithmic trading models and strategies is no simple task. To make matters worse the current state of crypto is highly volatile and rapidly changing. The market has become war zone due to regulations from the SEC and various governments targeting crypto exchanges. Despite all of the negative news, many traders are making it big in day-trading crypto assets.
In a previous post I wrote about our progress in making short-term predictions. In this post I take it to a next level. I will illustrate our efforts of how we are incorporating the predictions into a successful trading strategy.
Manual modelling
Developing an algorithmic model/strategy usually starts by looking at the raw data but more importantly analysing several indicators such as SMA, MACD, EMA and RSI. The whole point of the process is trying to find some patterns that are pretty obvious to the human eye, but also that these patterns are reoccurring throughout history and hopefully will continue to do so in the future.
In theory
Most strategies are based around making a profit, so people look for ways to detect a valley so they can trigger a buy signal, and then let the system wait until theres a peak to trigger a sell signal. This is risky business, since there are no guarantees, i.e.: a system cannot accurately tell (given historical events) whether that market price is at a valley or not?-?it can only make a calculated guess. And thats the whole point, we try to make a calculated guess, that is the plausibility of being at a valley/peak and triggering a trading signal (either buy or sell).
In reality
The reality is much more tricky than the theory. A system may indicate its at a valley, but a few minutes later the price drops even lower.
If you have ever written code for large software projects then you know that error/failure rate grows in proportion to every new line of code added. This means that the more code you write, the more mistakes/bugs/errors you induce?-?humans are not perfect, neither are programmers no matter how brilliant. When we write code we usually have a clear goal in mind, thus we know what the output should be given some clearly defined input. But try doing that with input date of (crypto-) assets (e.g. Bitcoin), youll quickly realize that its not a trivial thing to do. The input is never the same, and we cannot simply rely on a bunch of if this?-?do that code. However, thats the only language a computer understands, its our most reliable tool for the job.
To make our job easier we have to introduce math and statistics to aid us. This is done by creating indicators, as mentioned earlier, such as SMA and MACD. An indicator is a function that takes raw data, transforms it and spits something new out. Indicators make our lives easier in analyzing the raw market data, they allow us to detect/see patterns that we wouldnt otherwise see. If you know a tad about trading then youll know how useful the MACD, long & short SMA plots are.
Since indicators are solely based on historical data, they are not very good at making predictions, but neither completely useless. To illustrate this have a look at the following chart:
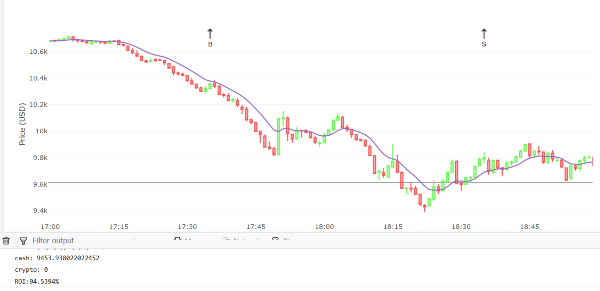
Manual model (1)
In the above we have the price of Bitcoin plotted out as candlesticks. Then I created an indicator (EMA) of some size, based of the Open and Close values. The next step would be to use code, that is if this?-?do that statements, to come up with a basic strategy that would have a positive ROI (incorporating trading fees). Remember my story of peaks & valleys earlier? Well here we see it in action. My algorithm uses the EMA indicator to generate a first buy signal (indicated by B on the chart), in this case its designed to anticipate a valley, because after rain usually comes sunshine. However, after this buy no sun came, but only more rain (the price kept going down). And then later a sell signal is generated at some local peak.
On this chart we can clearly see how a simple algorithm makes decisions. The sad part is that its decisions are not optimal, the reason is apparent since at each step, the algorithm can only look at the past?-?it cannot foretell the future to make the best decision. The other sad part is that such a simple algorithm has hard-coded parameters, such as the indicators parameters (e.g. EMA size). To us humans, we may look at these generated signals and say what a stupid decision?-?we cannot argue at all, a machine can only make the decisions we program it to do. If the parameters are sub-optimal, so is the outcome.
At the lower part of the image I indicate the ROI of the generated signals, which is slightly over 94%, meaning the system made a loss of about 6%?-?reason: it bought higher than it sold, and to make matters worse it paid a 0.1% fee on every trade.
Below is another scenario. This time we use three indicators, but only one is shown. The brown bars represent the MACD indicator, which is built up from two different EMA indicators:
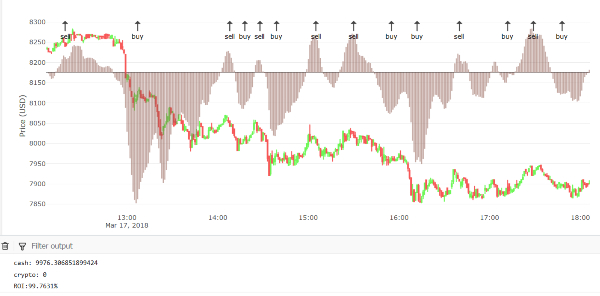
Manual model (2)
The basic idea behind using MACD as a trading strategy, is to yet again, detect peaks & valleys. This becomes apparent when you look at where the buy/sell signals appear, i.e. at some local MACDs peak/valley. This strategy appears to work better than the previous one, since the ROI is over 99% (i.e. it still made a loss of about 1%)?-?but we may not compare the two just like that because the previous example only had two trading signals and this one has way more.
Heres a third and final example. Below is a chart with signals based on the EMA signal (just like in our first case). But this time I have chosen a different region and more data.
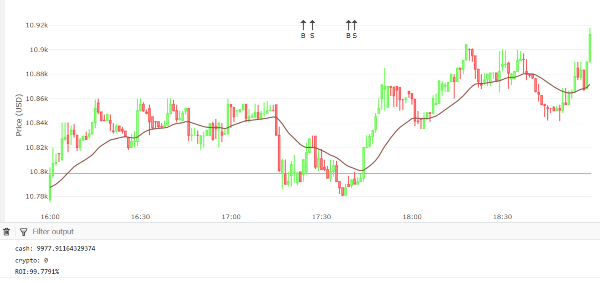
Manual model (3)
The ROI in the above is over 99%, just like in the case of our MACD. A closer look at the signals is pretty fascinating, it made two short buy/sell trades, which are only a few minutes apart. In this case I tried to let the system make a profit in a very short amount of time by leveraging the high volatility.
Verifying a strategy
These three examples were based on a very little data. Everything shown on the chart is what was used to generate the trading signals and compute the ROI. In practice, we have to run our algorithm on days, weeks, months or even years worth of data to verify its success rate. Unfortunately very few of these strategies proved to be successful in our tests. Actually, all of the above can generate ROI of over 100%?-?if there were no trading fees, since that is how exchanges prevent us from becoming millionaires overnight.
Deep data
Using raw market data (e.g. price & volume), combined with a few indicators will rarely yield a profitable trading strategy. Unless your algorithm is pretty sophisticated and well-designed?-?if so re-check everything because you may have a bug or unaccounted for scenario after all.
After a long time and countless attempts I did manage to come up with a few profitable trading algorithms. These were achieved by utilizing some default indicators which I had to adjust in several ways prior to applying. But more importantly, its the type of data I use which makes these methods successful. They are no longer based on just the price and/or volume, but take other factors into consideration such as sentiments (from our sentiment analyses).
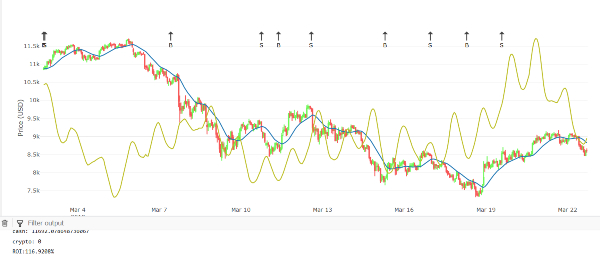
Manual model (5)
This strategy I continue to test, validate and optimize to this day?-?it appears to be the best Ive been able to come up with thus far. Notice how far apart the buy and sell signals are compared to our previous examples. Here they are many hours or even several days apart, while previously it was just minutes or a few hours. Before I sell my kidney and go all-in, I need to make sure it will really work. Hopefully within a few weeks Ill plug it in and write a new post showing my results.
Artificial Intelligence
One may develop as many models as he/she wishes to, or at least, as many he/she has the guts to. Its not a straightforward development process. Its pretty hard to test and verify new hypotheses while simultaneously tweaking its many parameters and trying different values. But what if we can use A.I. to help us come up with even better models and strategies?
This research area is even more complex than creating manual models, but its already the future?-?and if youre not with it, youre behind. At some point, if not already, A.I. will make better trading decisions (both long- & short-term) than humans do. If you are an A.I. researcher/developer, you know exactly how complex it is to make a system come up with a trading strategy. Its already complex enough to train it for carrying out simple tasks such as recognizing objects in pictures.
Hybrid modelling
Until some weeks ago I was using a manually designed strategy which used our predictions to generate trading signals. The results were pretty okay at that time, but they did not incorporate trading fees?-?so they actually are not so okay anymore.
Old predictions (1)
One of these strategies was to look at the highest and lowest prediction points and generate a sell/buy signal at these respective intervals. When you think about it, its definitely not going to be an optimal strategy by far. One may just as well start buying/selling randomly and have more luck through that. But I wouldnt throw this idea in the garbage just yet. In my previous post Ive illustrated our recent improvements of the predictions. So its definitely worth a shot re-running this old strategy on some new data.
What comes to mind is that these strategies are short-term, meaning they use whatever its predicted to make a decision in the moment. Since our predictions are usually no more than 3 to 15 minutes into the future, they will need to generate large enough margins to pay off the trading fees and thus generate a positive ROI.
There is one specific thing that I did add into the mix: predicting the next buy/sell signal. I wanted to teach our system to predict worthwhile buy/sell signals, the same way we make it predict the future price. To do this I first had to train the system on what a good buy and good sell position looks like. I did this by going over all the data, and using a look-ahead concept: given a position t, if in the near-future the price is going to drop a lot then t should indicate a sell signal?-?but if the price is going to go up then t should instead be a buy. The near-future was defined by the next 10 or-so intervals. Every other t would indicate a do nothing signal.
Hybrid model (1)
have taught the system that a sell signal equals the value of 100 ; a buy equals 50 and do nothing equals to zero. In the end the system does not fully respect my values, so it generates something either close to zero, around 50 or close to 100. But it does have some interesting results. If you look closely, it does indicate some interesting buy signals (= value 50), and then you have to make a guess for which near-future interval the sell signal corresponds with some buy signal. In the end this may prove a useful trading strategy, but its really hard to interpret and understand as is. I need to do a lot more research and development to improve it.
Q-learning
This is a form of reinforcement learning (RL), a technique for training A.I. to do certain stuff. RL is the trick behind teaching a machine how to play chess, Go and even Space Invaders.
RL trained-A.I. playing Breakout
If we can teach a machine how to play Pac Man, then we might as well teach it to generate buy/sell signals. This is exactly what I did. The logic behind it is to give the system a reward (like a pat on the back) when it makes a good decisions, and if not we punish it. The reward/punishment is expressed as a number, and so we train the system to optimize itself for obtaining the highest possible score. At start it makes a bunch of random guesses, gets its reward/punishment and then learns/re-trains itself based on these results. This process continues indefinitely, until we tell it to stop. We dont want the system to be over-fitted with respect to the input data, but we also dont want it to be super random?-?so we have to make it stop after a certain amount of iterations.
The implementation of Q-learning was done by using an open-source project. I only had to tweak & adjust it according to my needs. I also realized that the backbone of Q-learning systems was usually based on a feed forward neural network, I havent stumbled upon any solution that used a recurrent neural network instead (yet). But this is what I did implement. I quickly learned that training a system through RL is a very tedious and long process, it takes literally hours/days to complete, depending on the number of iterations and some other factors.
After many painful hours of training I did see some nice buy/sell signals appear, however to me they were more like random than intelligent. Overall Q-learning did not prove to be a successful technique, but I am going to improve it because I believe its a gold nugget.